k8s 入门 4:Pod 生命周期与容器探针
本文总结了 K8S Pod 的生命周期与容器探针的相关知识。
Pod 的生命周期
Pod 起始于 Pending 阶段, 如果至少其中有一个主要容器正常启动,则进入 Running,之后取决于 Pod 中是否有容器以失败状态结束而进入 Succeeded 或者 Failed 阶段。
Pod 的 status 字段是一个 PodStatus 对象,其中包含一个 phase 字段。Pod 的阶段(Phase)是 Pod 在其生命周期中所处位置的简单宏观概述。 该阶段并不是对容器或 Pod 状态的综合汇总,也不是为了成为完整的状态机。
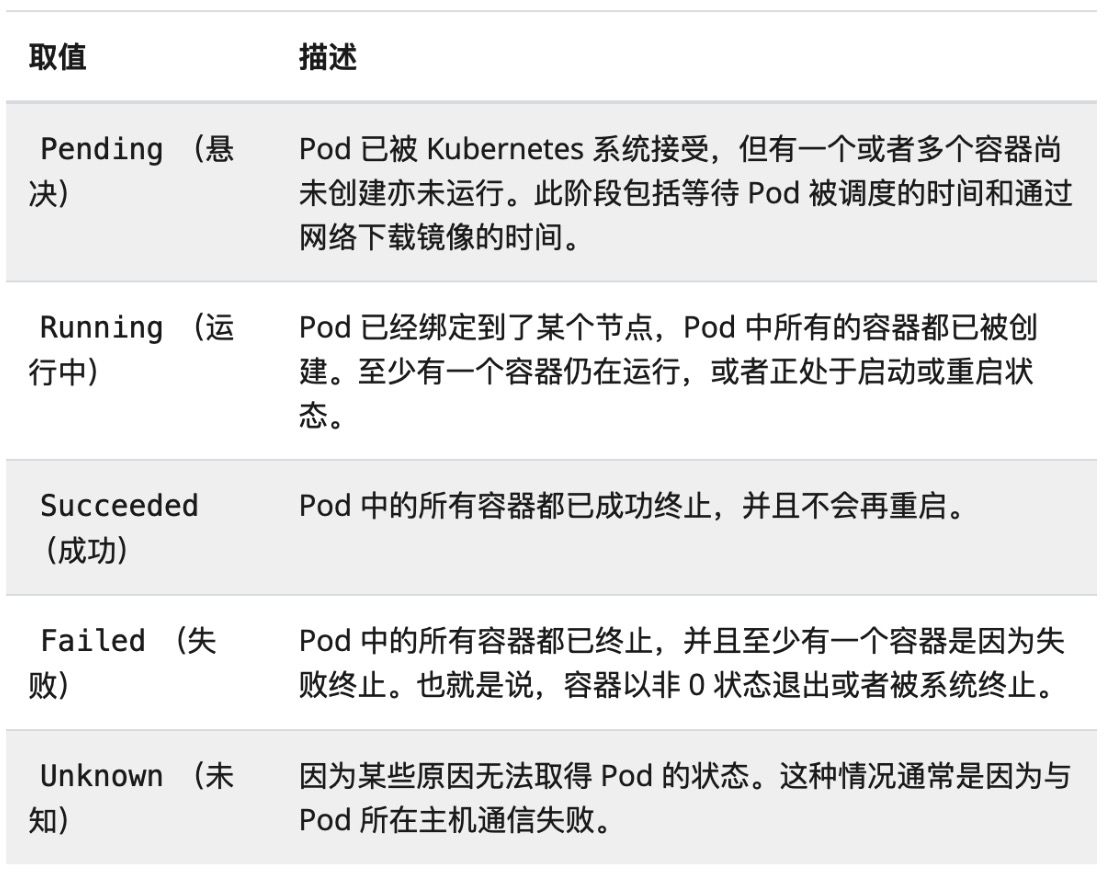
*说明:
当一个 Pod 被删除时,执行一些 kubectl 命令会展示这个 Pod 的状态为 Terminating(终止)。 这个 Terminating 状态并不是 Pod 阶段之一。 Pod 被赋予一个可以体面终止的期限,默认为 30 秒。 你可以使用 --force 参数来强制终止 Pod。*
如果一个节点死掉了,调度到该节点的 Pod 也被计划在给定超时期限结束后删除。
容器状态
调度器将 Pod 分派给某个节点,kubelet 就通过 CRI 开始为 Pod 创建容器。容器的状态有三种:Waiting(等待)、Running(运行中)和 Terminated(已终止)。
Waiting
容器还有些操作没有完成,如拉取镜像,或者向容器应用 Secret 数据等。
Running
容器正常执行,如果配置了 postStart 回调,回调已经执行完成。
Terminated
容器正常结束,或者因为某些原因失败,如果配置了 preStop 回调,该回调再进入此状态前执行。
容器探针
probe 是由 kubelet 对容器执行的定期诊断,方式有:
• 在容器内执行代码
• 发出一个网络请求
检查机制
1、exec
在容器内执行指定命令。如果命令退出时返回码为 0 则认为诊断成功。
2、grpc v1.27
使用 gRPC 执行一个远程过程调用,目标应该实现 gRPC 健康检查协议。如果响应的状态是 "SERVING",则认为诊断成功。
3、httpGet
执行 HTTP GET 请求,如果响应的状态码大于 200 且小于 400,则认为诊断成功。
4、tcpSocket
对 IP:PORT 执行 TCP 检测。如果端口打开,则认为诊断成功。
探测类型
livenessProbe
指示容器是否正常运行。如果存活探测失败,则 kubelet 会杀死容器,并且容器会根据其重启策略来决定未来。如果容器不提供存活探针,则默认状态为 Success。
什么时候用?
许多长时间运行的应用最终会进入损坏状态,除非重新启动,否则无法被恢复。 Kubernetes 提供了存活探针来发现并处理这种情况。
如果容器中的进程能够在遇到问题或不健康的情况下自行崩溃,则不一定需要存活态探针; kubelet 将根据 Pod 的 restartPolicy 自动执行修复操作。
如果你希望容器在探测失败时被杀死并重新启动,那么请指定一个存活态探针, 并指定 restartPolicy 为 "Always" 或 "OnFailure"。
readinessProbe
指示容器是否准别好为请求提供服务。如果就绪探针失败,Endpoint 控制器会从与 Pod 关联的所有服务的 Endpoint 列表中删除该 Pod 的 IP 地址。在 initialDelaySeconds 之前的状态默认是 Failure。若果容器不提供就绪探针,则默认状态是 Success。
什么时候用?
有时候,应用会暂时性地无法为请求提供服务。 例如,应用在启动时可能需要加载大量的数据或配置文件,或是启动后要依赖等待外部服务。 在这种情况下,既不想杀死应用,也不想给它发送请求。 Kubernetes 提供了就绪探针来发现并缓解这些情况。
1、如果要仅在探测成功时才开始向 Pod 发送请求流量;
2、希望容器在检测到某个特殊状态时自行进入维护状态;
3、应用程序对后端服务有严格的依赖性,同时实现存活态和就绪态探针。 当应用程序本身是健康的,存活态探针检测通过后,就绪态探针会额外检查每个所需的后端服务是否可用,避免将流量导向只能返回错误信息的 Pod。
4、容器需要再启动期间加载大型数据、配置文件或执行迁移且希望区分失败的和仍在处理的应用。
startupProbe
指示容器中的应用是否已经启动。如果提供了启动探针,则所有其他探针都会被禁用,直到此探针成功为止。如果启动探测失败,则 kubelet 会杀死容器,并且容器会根据其重启策略来决定未来。如果容器不提供存活探针,则默认状态为 Success。
什么时候用?
容器需要较长的启动时间,超出 initialDelaySeconds + failureThreshold × periodSeconds 总值。
参考
[1] Pod 生命周期
[2] 配置存活、就绪和启动探针
[3] gRPC 健康检查协议
[4] 为容器的生命周期事件设置处理函数