PostgreSQL 是如何执行一条查询的
本文介绍 PG 从接收到一条查询语句到输出结果的整个过程和一些主要操作。
测试数据集:pagila
概述
PG 是典型的 C/S 架构,客户端将 SQL 查询请求传给服务器,服务器收到请求后进行一系列处理,返会查询结果,结果可能是错误信息也可能是期望的查询结果。总的来说,在 PG 接收到一条查询请求到输出结果,会经历一下几个阶段:
- 解析(parser)
查询语句被传递给解析器(Parser),解析器进行词法分析、语法分析,如果有语法错误,直接返回错误信息;如果通过了语法检查,那么查询语句被转化成解析树——一种表示查询的结构化树形结构。
示例:
SELECT customer_name, balance FROM customers WHERE balance > 0 ORDER BY balance
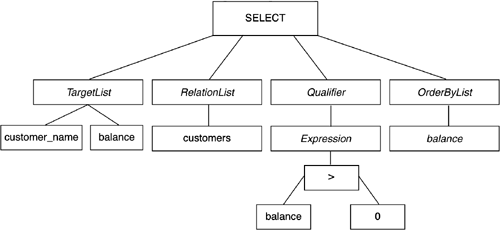
- 计划/优化(Planner/Optimizer)
计划器遍历查询树找到执行查询语句的所有可能计划。对于上面的 select 查询,计划可能是全表扫描( sequential scan),在有索引的情况下可能使用索引扫描(index scan);如果查询涉及到两个或者更多的表,计划器会建议 Join 表的几种方式。
优化分为两个层次:
- 逻辑优化:基于规则
- 物理优化:基于代价
逻辑优化是建立在关系代数基础上的优化,关系代数中有一些等价的逻辑变换规则,通过对关系代数表达式进行逻辑上的等价变换,可能会获得执行性能比较好的等式,这样就能提高查询的性能;物理优化则是在建立物理执行路径的过程中进行优化,关系代数虽然指定了两个关系如何进行连接操作,但是这时的连接操作符属于属于逻辑运算符,它并没有指定以何种方式实现这种逻辑连接操作,而查询的执行器是不认识关系代数中的逻辑连接操纵的,我们需要生成多个物理连接路径来实现关系代数中的逻辑连接操作,并且根据查询执行器的执行步骤,建立代价计算模型,通过计算所有的物理连接路径的代价,从中选择出最优的路径。
逻辑优化基于的等价变换公式:
- 交换律
- 结合律
- 分配律
- 串接律
物理优化基于的代价衡量方法:
**执行代价 = IO 代价 + CPU 代价 **
在 PG 中,逻辑优化又分为逻辑重写优化和逻辑分解优化。逻辑重写优化阶段主要是对查询树进行改造,而在逻辑分解阶段,会将查询树打散,再重新建立等价于查询树的逻辑关系。
逻辑重写优化大的基调是减少查询的层次、消除外连接操作、减少冗余操作。
- 执行(Executor)
当选择出代价最小的执行计划后,就进入执行的阶段了。
执行是通过一系列 Operator 来执行完成的。Operator 将一个后者多个输入集转换成一个结果集。比如顺序扫描(Seq Scan)操作将输入(物理表)转换成结果(内存表)并过滤掉不服务查询约束的数据条目;排序操作(Sort)将输入集按照一个或者多个建排序输出一个有序的结果集。
使用 explain 指令可以查看 PG 为一条查询选择的执行计划,参见另外一篇文章:读懂 PostgreSQL 的 Explain。
Operators
Seq Scan
Seq Scan 所有 operator 中最基础的,顾名思义就是从头到尾把整个表按顺序扫描一遍,在每一行上检验是否符合 where 的条件约束(如果有的话),符合就放进结果集中。
pagila=# explain select * from film where length < 100;
QUERY PLAN
---------------------------------------------------------
Seq Scan on film (cost=0.00..67.50 rows=377 width=390)
Filter: (length < 100)
(2 rows)
使用情况:
- 没有合适的索引;
- 有索引,但是可能的结果数据集较大,相比较而言从原表扫描比从索引扫描代价更低。
注意:
由于 PG 中 delete 操作的实现机制是打标记、 update 是先标记为删除再插入新的行,如果一个表存在频繁、大量的 delete 、update 操作,就会产生很多 ”dead rows“,这些行用户是感知不到的,但是会非常影响 Seq Scan 的执行效率。
Seq Scan 不需要整个过程执行完才输出第一行。
Index Scan
Index Scan 通过遍历索引结构查找数据。
下面是一个 btree 索引的简单例子,该索引存储的记录为整型并且只有一个字段:

以查找 49 为例,相比 Seq Scan 要遍历表中的每一条记录,Index Scan 的检索路径大大缩短了。另外,Seq Scan 按条的顺序返回结果,而索引结构是有序的,如果查询的是一个范围,那么通过索引返回的结果已经有序的,可以避免排序。
pagila=# explain select * from film where film_id = 1;
QUERY PLAN
------------------------------------------------------------------------
Index Scan using film_pkey on film (cost=0.28..8.29 rows=1 width=390)
Index Cond: (film_id = 1)
(2 rows)
Index Scan 不需要整个过程执行完才输出第一行。
Sort
Sort 对输入集进行排序,有两种策略:内存排序和磁盘排序。如果结果集的大小超过了 sort_mem 的,Sort 使用磁盘归并排序,如果没有超过,使用内存快速排序。
SQL 中出现 order by 一般会用到 Sort 。一些 Operator 要要它们操作的结果集有序,也可能用到 Sort,如 Unique、MergeJoin 等。
pagila=# explain select * from film order by length;
QUERY PLAN
----------------------------------------------------------------
Sort (cost=114.83..117.33 rows=1000 width=390)
Sort Key: length
-> Seq Scan on film (cost=0.00..65.00 rows=1000 width=390)
(3 rows)
Sort 需要整个过程执行完才输出第一行。
Unique
Unique 对输入集进行去重。Unique 需要输入集有序,所以通常是先对数据集执行 Sort 操作,才执行 Unique 操作。
pagila=# explain select distinct release_year from film;
QUERY PLAN
--------------------------------------------------------------------
Unique (cost=114.83..119.83 rows=1 width=4)
-> Sort (cost=114.83..117.33 rows=1000 width=4)
Sort Key: release_year
-> Seq Scan on film (cost=0.00..65.00 rows=1000 width=4)
(4 rows)
Unique 是工作机制是,遍历每一行,把当前行和前一行比较,如果相等则从结果集移除。
Unique 不需要整个过程执行完才输出第一行。
LIMIT
LIMIT 限制结果集的行数。
LIMIT 的工作机制是丢弃开头的 x 行,返回后面的 y 行,剩下的就不管了。如果查询中 出现了 LIMIT ,那么 LIMIT 的数量就是 y,如果出现 OFFSET ,那么 OFFSET 的数量就是 x,否则为 x 为 0。
pagila=# explain select * from film limit 5;
QUERY PLAN
----------------------------------------------------------------
Limit (cost=0.00..0.33 rows=5 width=390)
-> Seq Scan on film (cost=0.00..65.00 rows=1000 width=390)
(2 rows)
LIMIT 不需要整个过程执行完才输出第一行。
Aggregate
当查询中使用了聚合函数时,就会产生 Aggregate 操作,聚合函数有:AVG()、COUNT()、MAX()、MIN、STDDEV()、SUM() 和 VARIANCE()。
Aggregate 的工作机制是:读取输入集的所有行计算聚合值。
pagila=# explain select sum(length) from film;
QUERY PLAN
--------------------------------------------------------------
Aggregate (cost=67.50..67.51 rows=1 width=8)
-> Seq Scan on film (cost=0.00..65.00 rows=1000 width=2)
(2 rows)
Append
Append 是用来实现 UNION 、UNION ALL 的,它将两个以上的输入集转化成一个结果集。
pagila=# explain select first_name, last_name from actor union all select first_name, last_name from staff;
QUERY PLAN
---------------------------------------------------------------
Append (cost=0.00..17.30 rows=530 width=45)
-> Seq Scan on actor (cost=0.00..4.00 rows=200 width=13)
-> Seq Scan on staff (cost=0.00..13.30 rows=330 width=64)
(3 rows)
Result
- 执行一个查询,但并不是从表里面获取数据。
pagila=# explain select version();
QUERY PLAN
-------------------------------------------
Result (cost=0.00..0.01 rows=1 width=32)
(1 row)
- where 条件中包含与表数据无关的条件。
pagila=# explain select * from film where 1 <> 1;
QUERY PLAN
--------------------------------------------
Result (cost=0.00..0.00 rows=0 width=184)
One-Time Filter: false
(2 rows)
Nested Loop
Nested Loop 是用来执行 JOIN 的,需要两个输入集。
pagila=# explain select f.title, l.name from film f inner join language l on f.language_id = l.language_id;
Nested Loop (cost=0.15..280.37 rows=1000 width=99)
-> Seq Scan on film f (cost=0.00..65.00 rows=1000 width=19)
-> Index Scan using language_pkey on language l (cost=0.15..0.22 rows=1 width=88)
Index Cond: (language_id = f.language_id)
Nested Loop 的工作机制是没对一个输入集(外表)每一行,从另一个输入集(内表)查询符合 JOIN 条件的行。
执行计划中列出的第一个表就是外表,此例中为 film。
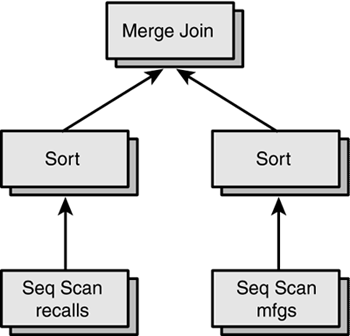
Merge Join
Merge Join 也是用来执行 JOIN 的,需要两个数据集,并且输入集需要有序。
pagila=# explain select f.title, l.name from film f inner join language l on f.language_id = l.language_id;
Merge Join (cost=47.14..171.89 rows=1000 width=99)
Merge Cond: (f.language_id = l.language_id)
-> Index Scan using idx_fk_language_id on film f (cost=0.28..109.28 rows=1000 width=19)
-> Sort (cost=46.87..48.49 rows=650 width=88)
Sort Key: l.language_id
-> Seq Scan on language l (cost=0.00..16.50 rows=650 width=88)
Merge Join 的工作机制类似与合并排序中合并两张表操作,用两个指针分别遍历两个有序的输入集,找到匹配的行。
Hash and Hash Join
Hash Join 也是用来执行 JOIN 的,需要两个数据集,通常和 Hash 一起工作。
pagila=# explain select f.title, l.name from film f inner join language l on f.language_id = l.language_id;
Hash Join (cost=24.62..92.27 rows=1000 width=99)
Hash Cond: (f.language_id = l.language_id)
-> Seq Scan on film f (cost=0.00..65.00 rows=1000 width=19)
-> Hash (cost=16.50..16.50 rows=650 width=88)
-> Seq Scan on language l (cost=0.00..16.50 rows=650 width=88)
Hash Join 的工作机制是通过 Hash 操作将内表转换为哈希表,对于外表的每一行,通过哈希表找匹配的行。
Group
Group 是用来执行 Group By 的,需要一个有序的输入集,一般和 Sort 一起出现。
Group (cost=114.83..119.83 rows=140 width=2)
Group Key: length
-> Sort (cost=114.83..117.33 rows=1000 width=2)
Sort Key: length
-> Seq Scan on film (cost=0.00..65.00 rows=1000 width=2)
GroupAggregate
类似 Aggregate,但是查询语句中有 group。
pagila=# explain select count(*) from film group by length;
QUERY PLAN
--------------------------------------------------------------------
GroupAggregate (cost=114.83..123.73 rows=140 width=10)
Group Key: length
-> Sort (cost=114.83..117.33 rows=1000 width=2)
Sort Key: length
-> Seq Scan on film (cost=0.00..65.00 rows=1000 width=2)
(5 rows)
Tid Scan
这个 Operator 基本不会被使用。每个数据行有一个隐藏的 ctid 属性,当通过 ctid 属性查询数据时,就会出现 Tid Scan。
pagila=# explain select title from film where ctid = '(0, 1)';
Tid Scan on film (cost=0.00..4.01 rows=1 width=21)
TID Cond: (ctid = '(0,1)'::tid)
Materialize
Materialize 操作会在一些子查询中出现,当 planner/optimizer 认为将子查询的结果物化以后再对物化结果从头遍历进行下一步操作开销更低。
pagila=# explain select * from film where language_id in (select language_id from language where name = 'English');
Nested Loop (cost=0.00..128.09 rows=5 width=390)
Join Filter: (film.language_id = language.language_id)
-> Seq Scan on film (cost=0.00..65.00 rows=1000 width=390)
-> Materialize (cost=0.00..18.14 rows=3 width=4)
-> Seq Scan on language (cost=0.00..18.12 rows=3 width=4)
Filter: (name = 'English'::bpchar)
Setop (Intersect, Intersect All, Except, Except All)
一种有四种 Setop,分别是 Setop Intersect,Setop Intersect All,Setop Except 和 Setop Except All,对应的 SQL 指令是 INTERSECT,INTERSECT ALL,EXCEPT 和 EXCEPT ALL。
参考
[1] Understanding How PostgreSQL Executes a Query
[2] PostgresSQL 技术内幕——查询优化深度探索
[3] Using EXPLAIN