PostgreSQL 是如何存储数据的
本文介绍 PostgreSQL 的 relation 存储结构。
Oid
每个数据库就对应一个 oid,可以从 pg_database 里查到:
pagila=# select datname, oid from pg_database;
postgres | 12994
testdb | 16384
template1 | 1
template0 | 12993
pagila | 17097
所有数据都存储在 $PGDATA 下,默认是 /var/lib/postgresql/data,这个目录下有很多文件,其中 base 目录就是所有数据藏身的地方:
root@ce31a4292dc9:/var/lib/postgresql/data/base# ls
1 12993 12994 16384 17097 pgsql_tmp
oid 全称 Object identifiers,是 PG 内部系统表用来作为唯一标识的,以数字命名的文件夹和上面查出来的 oid 是一一对应的。
Relation
进入到 17097,即 pagila 所在的文件夹,发现里面一些以数字命名的文件,可以猜测,这些也是 oid。
root@ce31a4292dc9:/var/lib/postgresql/data/base/17097# ls
112
113
1247
1247_fsm
1247_vm
1249
1249_fsm
1249_vm
1255
1255_fsm
1255_vm
1259
1259_fsm
1259_vm
12829
12829_fsm
12829_vm
...
这里存的其实是所有 relation 相关的数据文件。relation 是数据库理论中相比 table 更宽泛的概念。在 PG 中,table,index,sequences (本质上是单行的表),materialized views (本质上是记住查询的表),composite types 和 TOAST tables 都称为 relation。
可以从 pg_class 表中找到 relation 的 oid,以 film 表为例:
pagila=# select oid, relfilenode from pg_class where relname = 'film';
oid | relfilenode
-------+-------------
17155 | 17155
(1 row)
准确来说,relfilenode 的值才是文件名中的数字,只是目前这个值等于 oid。有些表可能不会以文件的形式存储,但是还是能在 pg_class 中查到,这时候 relfilenode 的值为零。
从 pg_class 中有两个影响存储结构的指标,reltuples 表示有多少行,relpages 表示存储这些行用了多少数据页。
pagila=# SELECT relname, oid, relpages, reltuples FROM pg_class where relname = 'film';
relname | oid | relpages | reltuples
---------+-------+----------+-----------
film | 17155 | 55 | 1000
(1 row)
Folk
一个 relation 通常并不是只对应一个数据文件,还有一些 folk。folk 有几种类型,每一种类型存储一种特定类型的数据。
root@ce31a4292dc9:/var/lib/postgresql/data/base/17097# ls -l | grep 17155
-rw------- 1 postgres postgres 450560 Mar 23 05:39 17155
-rw------- 1 postgres postgres 24576 Mar 23 05:39 17155_fsm
-rw------- 1 postgres postgres 0 Mar 23 05:28 17155_vm
上面列出的就是 film 表的三个 folk:main,fsm,vm。
main folk 即无后缀的文件,存储的就是表的数据,文件大小的默认上限为 1G,超过 1G 会创建新的,后面加上序号作为后缀,如 17155,17155.1,17155.2 ...
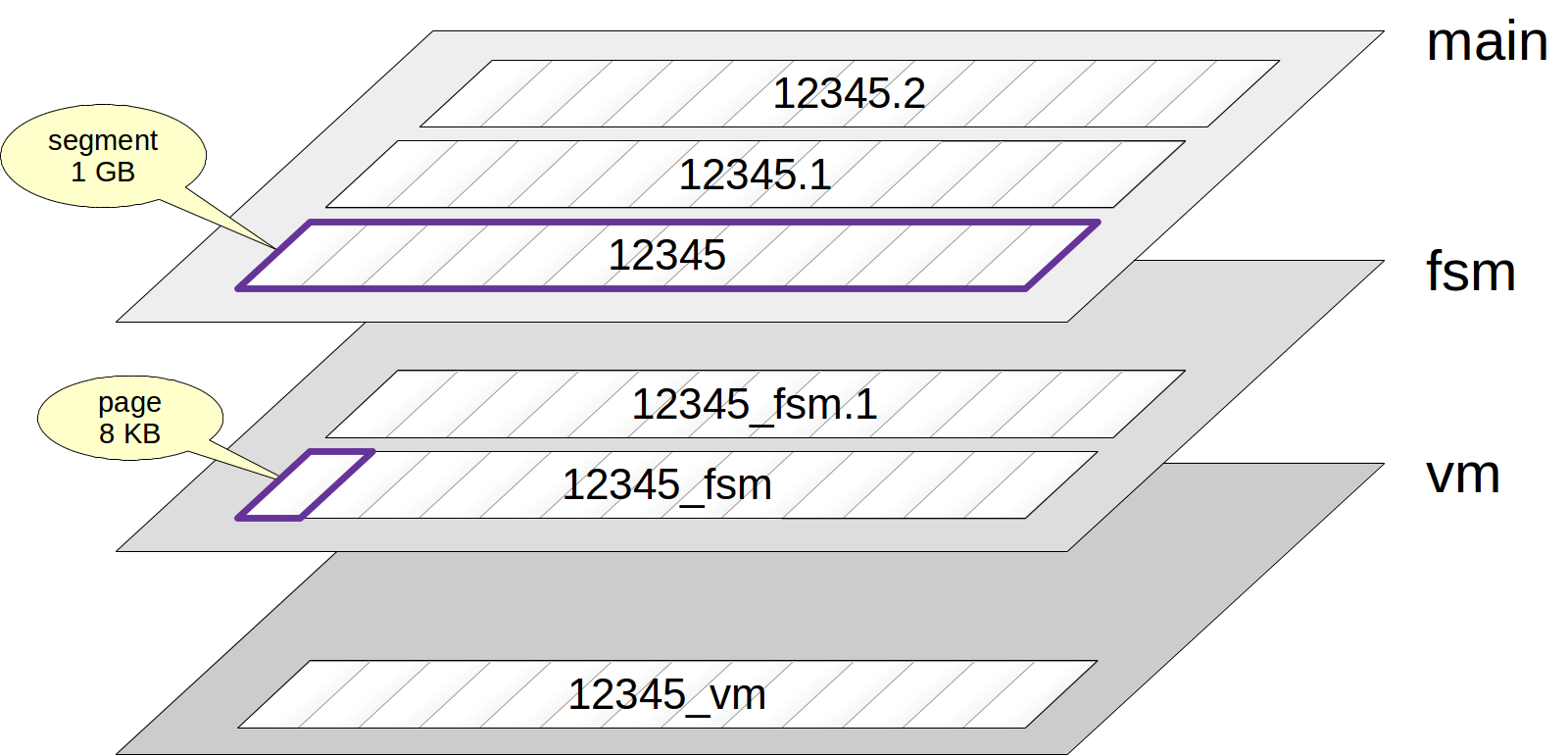
fsm folk 即 fsm 后缀的 folk,fsm 是 free space map 的缩写,它是用来追踪 page 里面可用空间的,方便为插入的新行快速找个合适的位置。
vm folk 即 vm 后缀的 folk,vm 是 visibility map 的缩写,它是用来追踪 page 里面最新版本的行。
除此之外,还有个 init folk,即 init 后缀的 folk,init 是 initialization 的缩写,只有在表被指定为 UNLOGGED 才会出现。UNLOGGED 的意思是,对它的操作不会为写入 write-ahead log (WAL)。因为不用写 WAL,它的速度很快,缺点是当出现故障时无法保证数据的一致性。
Page
注意上面查查的存储 film 表文件的大小 450560 和 page 数 55 之间的关系:
450560 / 55 = 8192。
在 PG 中,所有磁盘 I/O 是以 page 为单位计算的,默认情况下是 8192 字节(8k) 一个 page,即使只是从一张表里读取一条数据,PG 也会至少读取一个 page。当更新一行数据时,PG 将新的行添加到表的最末端,并把原来的行标记为无效。
不同 folk 中的 page 行为是相似的。page 首先被从磁盘读入 buffer cache,进程可以读取、修改里面的内容,在特定时候再写回磁盘。
page 有下面几个部分:
0 +-----------------------------------+
| header |
24 +-----------------------------------+
| array of pointers to row versions |
lower +-----------------------------------+
| free space |
upper +-----------------------------------+
| row versions |
special +-----------------------------------+
| special space |
pagesize +-----------------------------------+
可以使用 pageinspect 插件提供的方法查询各个部分的大小:
pagila=# CREATE EXTENSION pageinspect;
pagila=# SELECT lower, upper, special, pagesize FROM page_header(get_raw_page('film',0));
lower | upper | special | pagesize
-------+-------+---------+----------
96 | 464 | 8192 | 8192
(1 row)
header:其他部分的大小和一些 page 相关的信息
special space:索引相关信息
row versions:行数据真正存储的地方,再加上一些内部信息
array of pointers :到各个 row version 的指针数组
存储行数据的 page 叫 heap page;
存储索引数据数据的 page 叫 index page。
如果一个数据行太大,超过了 8k,一个 page 都存不下,这时候,PG 会将一部分数据写入 TOAST table。TOAST 的全称是 the oversized attribute storage technique。
Page Caching
所有数据库系统都受到下面两个规则的约束:
- 内存读写快,磁盘读写慢
- 内存资源紧张,磁盘资源富余
PG 通过将一些常用的数据保存在内存中以达到减少磁盘 I/O 的目的。服务器启动时,内存中会创建一个 buffer cache 的结构,其在组织上也是按 8k 一个 page,和磁盘上的 page 对应。
当从表中读取一行数据时,PG 将 heap page 读取到 buffer cache,如果空间不足,PG 会从 cache 移除一些,如果被移除的 page 有改动,那么它们会被写回磁盘。
Pointer
为什么需要指向 row version 的指针呢?
因为 index row 必须以某种方式找到 row version。找到 row version 需要 file number、page number,可用用 row 在 page 中的偏移量定位到 row version,但是这样不方便。最终的方案是 index 指向 pointer number,pointer 指向 row vertion 在 page 中的位置。
每个 pointer 占据 4 个字节,包含:
- row version 的位置
- row version 的大小
- row version 的状态
参考
[1] How PostgreSQL Organizes Data
[3] pg_class